What is ICR?
Intelligent Character Recognition (ICR) is an advanced form of Optical Character Recognition (OCR) – or basically a handwritten character recognition technology that uses algorithms to learn new and different styles of fonts and handwriting in order to ultimately improve character (text) recognition and accuracy.
Intelligent character recognition recognizes handwritten letters and numbers by analyzing features like lines, line intersections, and closed loops. It combines this feature analysis with traditional pixel-based processing to achieve high accuracy character recognition.
For example, an “O” is a closed loop, but a “C” is an open loop. These features are compared to vector-like representations of a character, rather than pixel-based representations. Because intelligent character recognition looks at features instead of pixels, it works well on multiple fonts and with handwritten characters.
Most intelligent character recognition software also use a neural network, which is like a recognition database where it stores these new handwriting patterns or styles.
What are the Benefits of Intelligent Character Recognition?
There are many benefits of using intelligent character recognition. Among those are:
- ICR makes OCR software more accurate as it recognizes a variety of new handwriting styles and fonts.
- You have more important data to make decisions from. If there isn’t an ICR component in the software, all handwritten data on documents and forms would not be captured and would not make it into a content management system.
- This could make a big difference to accounts payable departments as AP documents have important handwritten information on them.
- Reduced manual data entry work and fewer data errors. Any improvement or addition to OCR boosts text recognition and data accuracy. This means much less data entry work needed, and none of the errors that come with manual data entry. At the end of the day, this saves any business time and money.
- Improved data security. Handwritten information can often contain Personally Identifiable Information (PII) in the form of names, social security numbers, or drivers license numbers.
- If your software doesn’t have ICR, your enterprise may unknowingly circulate or store documents with PII, running the risk of privacy incidents. And privacy incidents can result in loss of employment, and civil or criminal penalties.
- ICR uses artificial intelligence and neural networks that help out a system to learn by itself with experience. This means that every time ICR experiences new data, that improves and upgrades its learning through artificial neuron networks, which improve the recognition database.
How Optical Character Recognition Works Without ICR
Traditional OCR uses a “matrix matching” algorithm to identify characters using pattern recognition. The character on the document’s image may look like this:

It is compared to a stored example that looks like this:

By comparing a matrix of pixels between the character on the image and the stored example, the software determines the character is a “G”.
This seems like a good approach – but beware of the pitfalls. Because it is comparing text to stored examples pixel by pixel, the text must be very similar.
Even if there are hundreds of examples stored for a single character, problems often arise when matching text on poor quality images or using uncommon fonts.
ICR vs. OCR – What’s the Difference?
We have talked about the two technologies, from a technical perspective. But what are actual reasons why businesses use OCR vs ICR, and vice versa?
ICR
- ICR recognizes text in images, handwritten forms, etc.
- ICR does not require templates to be created.
- ICR is adaptive and can be changed based on document layout changes through training.
- ICR is a subset of OCR technology.
- ICR is generally set up to recognize handwriting.
- It can recognize complex writing fonts and styles.
- It is more detailed and a more involved technology
- ICR will only flag inconsistencies or mathematical errors and asks human reviewers to verify.
OCR
- OCR recognizes text in documents.
- In most document capture software (especially legacy software), templates have to be manually created to enable OCR.
- Grooper does not require templates to be created to enable high quality OCR.
- OCR is great for companies who have a very structured and unchanging format for documents.
- OCR is a vast technology.
- OCR primarily focuses on printed documents.
- It has a limited ability to read handwriting and complicated fonts.
- It does not incorporate details in the documents.
- Manual intervention and review are required for OCR-based software.
How Does ICR Work?
Intelligent character recognition engines work by combining both traditional and feature-based OCR techniques. The results of both algorithms are combined to produce the best matching result. Each character is given a “confidence score,” which corresponds to how closely the character pixels or features match or a combination of the two.
Even with this blended approach the typical OCR villains are on the attack: poor document quality, multiple font types, and different font sizes.
What is this character? Is it an “O”, “0”, “C” or “G”? Is it even a character or letter at all? Very hard to tell, especially for a machine.

So intelligent character recognition must make a decision and it may not make sense within the context of the word or sentence. If a human can’t read the character, then OCR will certainly have trouble.
Specifically, here is how ICR works in document extraction in enterprise settings:
- Documents are loaded into the OCR / ICR scanner.
- Document images are read in detail for handwritten text and fonts, which are interpreted automatically, compared to pre-existing databases.
- Data is extracted from documents.
- If any data is flagged by the document processing system, that extracted data is verified by human reviewers.
- Otherwise, all documents are processed, and the extracted data is entered into line-of-business systems (such as accounts payable systems).
How Intelligent Character Recognition Uses Features
ICR decomposes characters into their component features rather than by comparing pixels to known examples.
So instead of using pixels to recognize this character…
Feature matching is used. It’s often easier for software to figure out what character this is by looking at features that make up a character instead of random pixels. The result is that the margin of error is less. These orange lines are a stored glyph for the letter ‘G’.

So ICR software compares the shapes in it’s stored glyphs to the character that was written or typed.

Now you know why intelligent character recognition an improvement over standard OCR is.
OCR Post-Processing to the Rescue
Without additional context, character recognition errors make sense. Even if the character isn’t discernable, a human knows “ballboy” is an indie band from Scotland and “bollboy” is just gibberish:
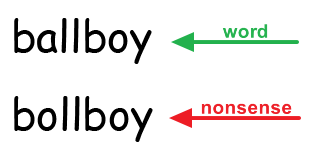
The most common post-processing done by OCR engines is basic spell correction. Often, errors from poor recognition result in small spelling mistakes. All commercial OCR engines compare results with a lexicon of common words and attempt to make logical replacements.
What is Intelligent Word Recognition?
Intelligent word recognition (IWR) recognizes and extracts hand-written and printed data, but also cursive handwriting.
ICR software recognizes on the character level, whereas IWR looks at full words and phrases. It also has the capability of capturing unstructured information and is a different evolution of hand-written ICR.
This is not to say that intelligent word recognition is going to or should replace traditional OCR or ICR systems, as IWR is optimized for processing real-world documents that have a free form and hard-to-recognize data fields and as such are not suitable for ICR. (See example above).
So the best application of IWR is on documents where OCR or ICR would have a very tough time (cursive handwriting); but also with enough instances where the other option (manual entry) would involve substantial manual work.
How Does ICR Recognize Proper Nouns and Other Important Words?
If you need to recognize important words that are not in a lexicon of common words, this is where intelligent character recognition really shines. There are two easy ways to identify incorrect characters:
- The easiest way is to import custom lexicons for words related to your organization or industry. You may have medical terms or even customer / company information that you need to match against. Using a custom lexicon will provide even better chances at finding the right match.
- Another method for improving OCR character accuracy is something called “fuzzy matching.” Fuzzy matching is a method of providing weighted thresholds to characters and allowing the software to substitute characters based on likely good replacements. For example, the software would be allowed to try an “o” when a “0” provides a bad result. Same for an “l” instead of a “1”, etc.
Out-of-the-box OCR like Transym, Tesseract, Azure, ABBYY intelligent character recognition, and Prime all provide more accurate OCR results when combined with an advanced character recognition solution, like Grooper.
Applications of Intelligent Character Recognition
Intelligent character recognition was created for the purpose of real-world data capture off physical documents and intelligently converting it into usable electronic forms. ICR is being used every day by these industries:
- Financial institutions such as banks and credit unions use ICR to streamline workflows through Optical Mark Recognition to get information off loan applications, forms, surveys and even checks.
- Every single industry deals with massive amounts of accounts payable data, in the form of invoices, receipts, bills of lading, etc. ICR technology can be a vital component to achieving the highest rates of recognition accuracy, which drastically cuts down on human time needed to key the data into line-of-business systems.
- E-commerce and online-based businesses use ICR to collect electronic signatures and log them into databases to assist with know-your-customer documentation.