Third, certainty is driven by feedback, or lack thereof.
If a learner is presented with questions, and randomly get’s them correct, it makes sense that they would feel certain they have an understanding they likely do not truly have.
And without feedback, the level of certainty will be driven by irrelevant factors.
Try this example. Ugly old woman, or beautiful princess?
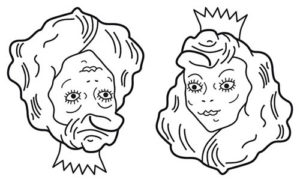
If I’d only shown you one of the pictures, your answer would have been correct, but you might not have known the reality of the picture. How will we build algorithms that don’t form permanent certainty based on initial training or feedback?